









Clinical research that uses artificial intelligence (AI) and big data may aid the prediction and/or detection of subclinical cardiovascular diseases by providing additional knowledge about disease onset, progression or outcome. Clinical decision-making, disease diagnostics, risk prediction or individualised therapy may be informed by insights obtained from AI algorithms. As health records have become electronic, data from large populations are becoming increasingly accessible.1 The use of AI algorithms in electrophysiology may be of particular interest as large data sets of ECGs are often readily available. Moreover, data are continuously generated by implantable devices, such as pacemakers, ICDs or loop recorders, or smartphone and smartwatch apps.2–6
Interpretation of ECGs relies on expert opinion and requires training and clinical expertise which is subjected to considerable inter- and intra-clinician variability.7–12 Algorithms for the computerised interpretation of ECGs have been developed to facilitate clinical decision-making. However, these algorithms lack accuracy and may provide inaccurate diagnoses which may result in misdiagnosis when not reviewed carefully.13–18
Substantial progress in the development of AI in electrophysiology has been made, mainly concerning ECG-based deep neural networks (DNNs). DNNs have been tested to identify arrhythmias, to classify supraventricular tachycardias, to predict left ventricular ejection fraction, to identify disease development in serial ECG measurements, to predict left ventricular hypertrophy and to perform comprehensive triage of ECGs.6,19–23 DNNs are likely to aid non-specialists with improved ECG diagnostics and may provide the opportunity to expose yet undiscovered ECG characteristics that indicate disease.
With this progress, the challenges and threats of using AI techniques in clinical practice become apparent. In this narrative review, recent progress of AI in the field of electrophysiology is discussed together with its opportunities and threats.
A Brief Introduction to Artificial Intelligence
AI refers to mimicking human intelligence in computers to perform tasks that are not explicitly programmed. Machine learning (ML) is a branch of AI concerned with algorithms to train a model to perform a task. Two types of ML algorithms are supervised learning and unsupervised learning. Supervised learning refers to ML algorithms where input data are labelled with the outcome and the algorithm is trained to approximate the relation between input data and outcome. In unsupervised learning, input data are not labelled and the algorithm may discover data clusters in the input data.
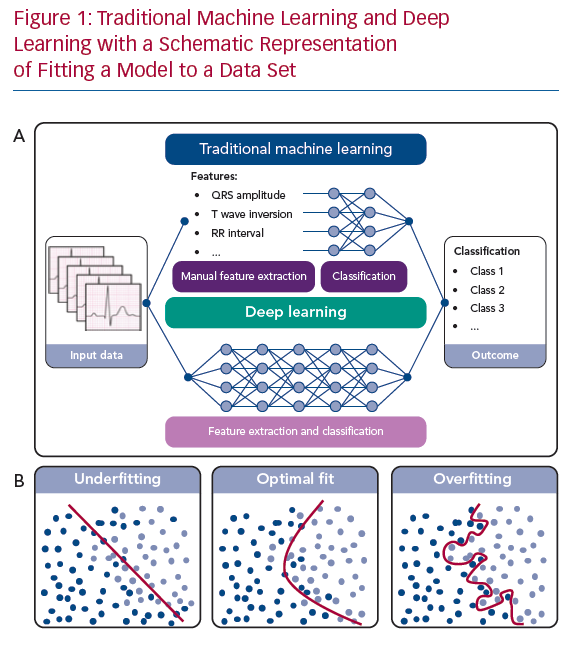
In ML, an algorithm is trained to classify a data set based on several statistical and probability analyses. In the training phase, model parameters are iteratively tuned by penalising or rewarding the algorithm based on a true or false prediction. Deep learning is a sub-category of ML that uses DNNs as architecture to represent and learn from data. The main difference between deep learning and other ML algorithms is that DNNs can learn from raw data, such as ECG waveforms, in an end-to-end manner with extraction and classification united in the algorithm (Figure 1a). For example, in ECG-based DNNs, a matrix containing the time-stamped raw voltage values of each lead are used as input data. In other ML algorithms, features like heart rate or QRS duration are manually extracted from the ECG and used as input data for the classification algorithm.
To influence the speed and quality of the training phase, the setting of hyperparameters, such as the settings of the model architecture and training, is important. Furthermore, overfitting or underfitting the model to the available data set must be prevented. Overfitting can occur when a complex model is trained using a small data set. The model will precisely describe the training data set but fail to predict outcomes using other data (Figure 1b). On the other hand, when constraining the model too much, underfitting occurs (Figure 1b), also resulting in poor algorithm performance. To assess overfitting, a data set is usually divided into a training data set, a validation data set and a test data set, or resampling methods are used, such as cross-validation or bootstrapping.24
To train and test ML algorithms, particularly DNNs, it is preferable to use a large data set, known as big data. Performance of highly dimensional algorithms – e.g. algorithms with many model parameters such as DNNs – depends on the size of the data set. For deep learning, more data is often required as DNNs have many non-linear parameters and non-linearity increases the flexibility of an algorithm. The size of a training data set has to reasonably approximate the relation between input data and outcome and the amount of testing data has to reasonably approximate the performance measures of the DNN.
Determining the exact size of a training and testing data set is difficult.25,26 It depends on the complexity of algorithm (e.g. the number of variables), the type of the algorithm, the number of outcome classes and the difficulty of distinguishing between outcome classes as inter-class differences might be subtle. Therefore, size of the data set should be carefully reviewed for each algorithm. A rule of thumb for the adequate size of a validation data set is 50–100 patients per outcome class to determine overfitting. Recent studies published in the field of ECG-based DNNs used between 50,000 and 1.2 million patients.6,19,21,27
Prerequisites for AI in Electrophysiology
Preferably, data used to create AI algorithms is objective, as subjectivity may introduce bias in the algorithm. To ensure clinical applicability of created algorithms, ease of access to input data, difference in data quality in different clinical settings as well as the intended use of the algorithm should be considered. In this section, we mainly focus on the data quality of ECGs, as these data are easily acquired and large data sets are readily available.
Technical Specifications of ECGs
ECGs are obtained via electrodes on the body surface using an ECG device. The device samples the continuous body surface potentials and the recorded signals are filtered to obtain a clinically interpretable ECG.28 As the diagnostic information of the ECG is contained below 100 Hz, a sampling rate of at least 200 Hz is required according to the Nyquist theorem.29–33 Furthermore, an adequate resolution of at least 10 µV is recommended to also obtain small amplitude fluctuations of the ECG signal. In the recorded signal, muscle activity, baseline wander, motion artefacts and powerline artefacts are also present, distorting the measured ECG. To remove noise and obtain an easily interpretable ECG, a combination of a high-pass filter of 0.67 Hz and a low-pass filter of 150–250 Hz is recommended, often combined with a notch filter of 50 Hz or 60 Hz. The inadequate setting of these filters might result in a loss of information such as QRS fragmentation or notching, slurring or distortion of the ST segment. Furthermore, a loss of QRS amplitude of the recorded signal might be the result of the inappropriate combination of a high frequency cut-off and sampling frequency.28,34 ECGs used as input for DNNs are often already filtered, thus potentially relevant information might already be lost. As DNNs process and interpret the input data differently, filtering might be unnecessary and potentially relevant information may be preserved. Furthermore, as filtering strategies differ between manufacturers and even different versions of ECG devices, the performance of DNNs might be affected when ECGs from different ECG devices are used as input data.
Apart from applied software settings, such as sampling frequency or filter settings, the hardware of ECG devices also differs between manufacturers. Differences in analogue to digital converters, type of electrodes used, or amplifiers also affect recorded ECGs. The effect of input data recorded using different ECG devices on the performance of AI algorithms is yet unknown. However, as acquisition methods may differ significantly between manufacturers, the performance of algorithms are likely to depend on the type or even version of the device.35 Testing the performance of algorithms using ECGs recorded by different devices would illustrate the effect of these technical specifications on performance and generalisability.
ECG Electrodes
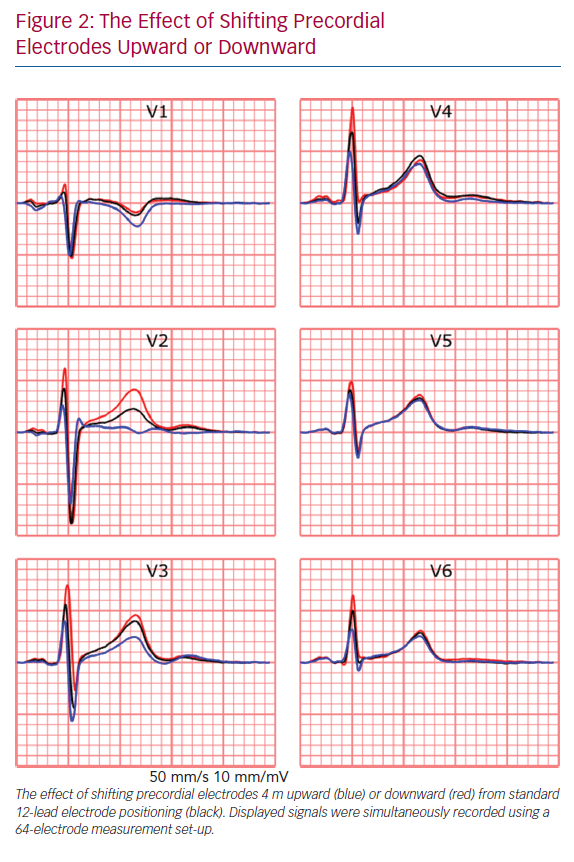
The recorded ECG is affected by electrode position with respect to the anatomical position of the heart and displacement of electrodes may result in misdiagnosis in a clinical setting.36,37 For example, placement of limb electrodes on the trunk significantly affects the signal waveforms and lead reversal may mimic pathological conditions.38–41 Furthermore, deviations in precordial electrode positions affect QRS and T wave morphology (Figure 2). Besides the effect of cardiac electrophysiological characteristics like anisotropy, His-Purkinje anatomy, myocardial disease and cardiac anatomy on measured ECGs, cardiac position and cardiac movement also affect the ECG.42–45
Conventional clinical ECGs mostly consist of the measurement of eight independent signals; two limb leads and six precordial leads (Figure 3b). The remaining four limb leads are derived from the measured limb leads. However, body surface mapping studies identified the number of signals containing unique information up to 12 for ventricular depolarisation and up to 10 for ventricular repolarisation.46 Theoretically, to measure all information about cardiac activity from the body surface, the number of electrodes should be at least the number of all unique measurements. However, conventional 12-lead ECG is widely accepted for most clinical applications. An adjustment of a lead position is only considered when a posterior or right ventricle MI or Brugada syndrome is suspected.27,47–50
The interpretation of ECGs by computers and humans is fundamentally different and factors like electrode positioning or lead misplacement might influence algorithms. However, the effect of electrode misplacement or reversal, disease-specific electrode positions or knowledge of lead positioning on the performance on DNNs remains to be identified. A recent study was able to identify misplaced chest electrodes, implying that the effect of electrode misplacement might be able to be identified and acknowledged by algorithms.51 Studies have suggested that DNNs can achieve similar performance when fewer leads are used.50
ECG Input Data Format
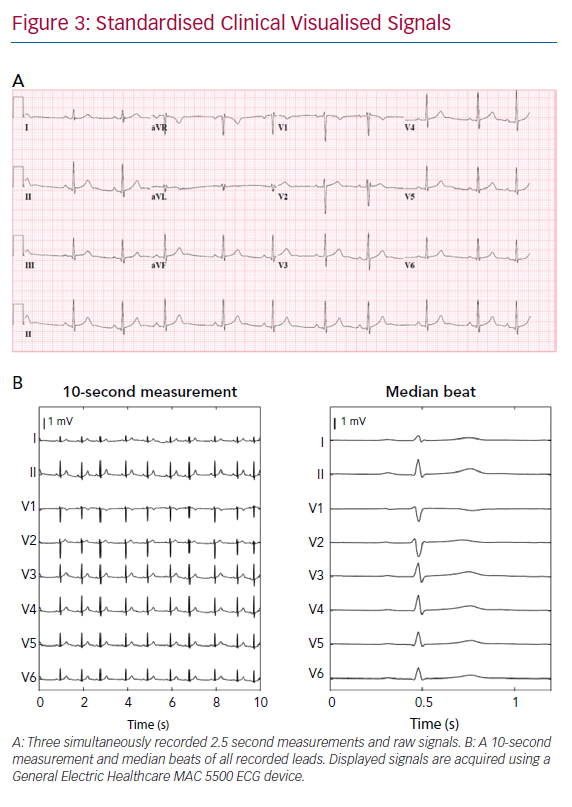
ECGs can be obtained from the electronic database in three formats – visualised signals (as used in standard clinical practice), raw ECG signals or median beats. Raw signals are preferable for input for DNNs as visualised signals require digitisation, which results in a loss of signal resolution. Furthermore, raw ECG signals often consist of a continuous 10-second measurement of all recorded leads, whereas visualised signals may consist of 2.5 seconds per lead with only three simultaneously recorded signals per 2.5 seconds (Figure 3). A median beat per lead can also be used, computed from measured raw ECG signals or digitised visualised signals. Using the median beat might reduce noise, as noise is expected to cancel out by averaging all beats. Therefore, subtle changes in cardiac activation, invisible due to noise might become distinguishable for the algorithm. The use of the median beat may allow for precise analysis of waveform shapes or serial changes between individuals but rhythm information will be lost.
Opportunities for Artificial Intelligence in Electrophysiology
Enhanced Automated ECG Diagnosis
An important opportunity of AI in electrophysiology is the enhanced automated diagnosis of clinical 12-lead ECGs.8,11,12,20,52–54 Adequate computerised algorithms are especially important when expert knowledge is not readily available, such as in pre-hospital care, non-specialist departments, or facilities that have minimal resources. If high-risk patients can be identified correctly, time-to-treatment can be reduced. However, currently available computerised ECG diagnosis algorithms lack accuracy.11 Progress has been made in using DNNs to automate diagnosis or triage ECGs to improve time-to-treatment and reduce workload.19,55 Using very large data sets, DNNs can achieve high diagnostic performance and outperform cardiology residents and non-cardiologists.6,19 Moreover, progress has been made in using ECG data for predictive modelling for AF in sinus rhythm ECGs or for the screening of hypertrophic cardiomyopathy.56–58
Combining Other Diagnostic Modalities with ECG-based DNN
Some studies have suggested the possibility of using ECG-based DNNs with other diagnostic modalities to screen for disorders that are currently not associated with the ECG. In these applications, DNNs are thought to be able to detect subtle ECG changes. For example, when combined with large laboratory data sets, patients with hyperkalaemia could be identified, or when combined with echocardiographic results, reduced ejection fraction or aortic stenosis could be identified. The created DNNs identified these three disorders from the ECG with high accuracy.21,50,59 As a next step, supplementing ECG-based DNNs with body surface mapping data with a high spatial resolution (e.g. more than 12 measurement electrodes), inverse electrocardiography data or invasive electrophysiological mapping data, may result in the identification of subtle changes in the 12-lead ECG as a result of pathology.
Artificial Intelligence for Invasive Electrophysiological Studies
The application of AI before and during complex invasive electrophysiological procedures, such as electroanatomical mapping, is another major opportunity. By combining information from several diagnostic tools such as MRI, fluoroscopy or previous electroanatomical mapping procedures, invasive catheter ablation procedure time might be reduced through the accelerated identification of arrhythmogenic substrates. Also, new techniques such as ripple mapping may be of benefit during electroanatomical mapping studies.60 Recent studies suggest that integration of fluoroscopy and electroanatomical mapping with MRI is feasible using conventional statistical techniques or ML, whereas others suggest the use of novel anatomical mapping systems to circumvent fluoroscopy.61–64 Furthermore, several ML algorithms have been able to identify myocardial tissue properties using electrograms in vitro.65
Ambulatory Device-based Screening for Cardiovascular Diseases
One of the major current challenges in electrophysiology is the applicability of ambulatory rhythm devices in clinical practice. Several tools, such as implantable devices or smartwatch and smartphone-based devices, are becoming more widely used and continuously generate large amounts of data which would be impossible to evaluate manually.66 Arrhythmia detection algorithms based on DNNs trained on large cohorts of ambulatory patients with a single-lead plethysmography or ECG device have shown similar diagnostic performance as cardiologists or implantable loop recorders.2,3,6 Another interesting application of DNN algorithms are data from intracardiac electrograms before and during the activation of the defibrillator. Analysis of the signals before the adverse event might provide insight into the mechanism of the ventricular arrhythmia, providing the clinician with valuable insights. Continuous monitoring also provides the possibility of identifying asymptomatic cardiac arrhythmias or detecting post-surgery complications. Early detection might overcome serious adverse events and significantly improve timely personalised healthcare.6,19
A promising benefit of smartphone applications for the early detection of cardiovascular disease is in early detection of AF. As AF is a risk factor for stroke, early detection may be important to prompt adequate anticoagulant treatment.67–69 An irregular rhythm can be accurately detected using smartphone or smartwatch-acquired ECGs. Even predicting whether a patient will develop AF in the future using smartphone-acquired ECGs recorded during sinus rhythm has been recently reported.69,70 Also, camera-based photoplethysmography recordings can be used to differentiate between irregular and regular cardiac rhythm.71,72 However, under-detection of asymptomatic AF is expected as the use of applications requires active use and people are likely to only use applications when they have a health complaint. Therefore, a non-contact method with facial photoplethysmography recordings during regular smartphone use may be an interesting option to explore.70,73,74
Apart from the detection of asymptomatic AF, the prediction or early detection of ventricular arrhythmias using smartphone-based techniques are potentially clinically relevant. For example, smartphone-based monitoring of people with a known pathogenetic mutation might aid the early detection of disease onset. In some pathogenetic mutations, this may be especially relevant as sudden cardiac death can be the first manifestation of the disease. In these patients, close monitoring to prevent these adverse events by starting early treatment when subclinical signs are detected may provide clinical benefit.
Threats of Artificial Intelligence in Electrophysiology
Data-driven Versus Hypothesis-driven Research
Data from electronic health records are almost always retrospectively collected, leading to data-driven research, instead of hypothesis-driven research. Research questions are often formulated based on readily available data, which increases the possibility of incidental findings and spurious correlations. While correlation might be sufficient for some predictive algorithms, causal relationships remain of the utmost important to define pathophysiological relationships and ultimately for the clinical implementation of AI algorithms. Therefore, big data research is argued to be in most cases solely used to generate hypotheses and controlled clinical trials remain necessary to validate these hypotheses. When AI is used to identify novel pathophysiological phenotypes, e.g. with specific ECG features, sequential prospective studies and clinical trials are crucial.75
Input Data
Adequate labelling of input data is important for supervised learning.18,76,77 Inadequate labelling of ECGs or the presence of pacemaker artefacts, comorbidities affecting the ECG or medication affecting the rhythm or conduction, might influence the performance of DNNs.13–18 Instead of true disease characteristics, ECG changes due to clinical interventions are used by the DNN to classify ECGs. For example, a DNN using chest X-rays provided insight into long-term mortality, but the presence of a thoracic drain and inadequately labelled input data resulted in an algorithm that was unsuitable for clinical decision-making.77–80 Therefore, the critical review of computerised labels and the identification of important features used by the DNN are essential.
Data extracted from ambulatory devices consist of real-time continuous monitoring data outside the hospital. As the signal acquisition is performed outside a standardised environment, signals are prone to errors. ECGs are more often exposed to noise due to motion artefacts, muscle activity artefacts, loosened or moved electrodes and alternating powerline artefacts. To accurately assess ambulatory data without the interference of artefacts, signals should be denoised or a quality control mechanism should be implemented. For both methods, noise should be accurately identified and adaptive filtering or noise qualification implemented.81–83 However, as filtering might remove information, rapid real-time quality reporting of the presence of noise in the acquired signal is thought to be beneficial. With concise instructions, users can make adjustments to reduce artefacts and the quality of the recording will improve. Different analysis requires different levels of data quality and through classification recorded data quality, the threshold for user notification can be adjusted per analysis.84,85
Generalisability and Clinical Implementation
With the increasing number of studies on ML algorithms, generalisability and implementation is one of the most important challenges to overcome. Diagnostic or prognostic prediction model research, from simple logistic regression to highly sophisticated DNNs, is characterised by three phases:
- Development and internal validation.
- External validation and updating for other patients.
- Assessment of the implementation of the model in clinical practice and its impact on patient outcomes.86,87
During internal validation, the predictive performance of the model is assessed using the development data set through train-test splitting, cross-validation or bootstrapping. Internal validation is however insufficient to test generalisability of the model in ‘similar but different’ individuals. Therefore, external validation of established models is important before clinical implementation. A model can be externally validated through temporal (same institution, later period), geographical (a different institution with a similar patient group) or domain (different patient group) validation. Finally, implementation studies, such as cluster randomised trials, before and after studies or decision-analytic modelling studies, are required to assess the effect of implementing the model in clinical care.86,87
Most studies in automated ECG prediction and diagnosis performed some type of external validation. However, no study using external validation in a different patient group or implementation study has been published so far. A study has shown similar accuracy to predict low ejection fraction from the ECG using a DNN through temporal validation as in the development study.88 A promising finding was a similar performance of the algorithm for different ethnic subgroups, even if the algorithm was trained on one subgroup.89 As a final step to validate this algorithm, a cluster randomised trial is currently being performed. This might provide valuable insight into the clinical usefulness of ECG-based DNNs.90
Implementation studies for algorithms using ambulatory plethysmography and ECG data are ongoing. For example, the Apple Heart Study assessed the implementation of smartphone-based AF detection.5 More than 400,000 patients who used a mobile application were included, but only 450 patients were analysed. Implementation was proven feasible as the number of false alarms was low, but the study lacks insight into the effect of smartphone-based AF detection on patient outcome. Currently, the Heart Health Study Using Digital Technology to Investigate if Early AF Diagnosis Reduces the Risk of Thromboembolic Events Like Stroke IN the Real-world Environment (HEARTLINE; NCT04276441) is randomising patients to use the smartwatch monitoring device. The need for treatment with anticoagulation of patients with device-detected subclinical AF is also being investigated.4
A final step for the successful clinical implementation of AI is to inform its users about adequate use of the algorithm. Standardised leaflets have been proposed to instruct clinicians when, and more importantly when not, to use an algorithm.91 This is particularly important if an algorithm is trained on a cohort using a specific subgroup of patients. Then, applying the model to a different population may potentially result in misdiagnosis. Therefore, describing the predictive performance in different subgroups, such as different age, sex, ethnicity and disease stage, is of utmost importance as AI algorithms are able to identify these by themselves.89,92–94 However, as most ML algorithms are still considered to be ‘black boxes’, algorithm bias might remain difficult to detect.
Interpretability
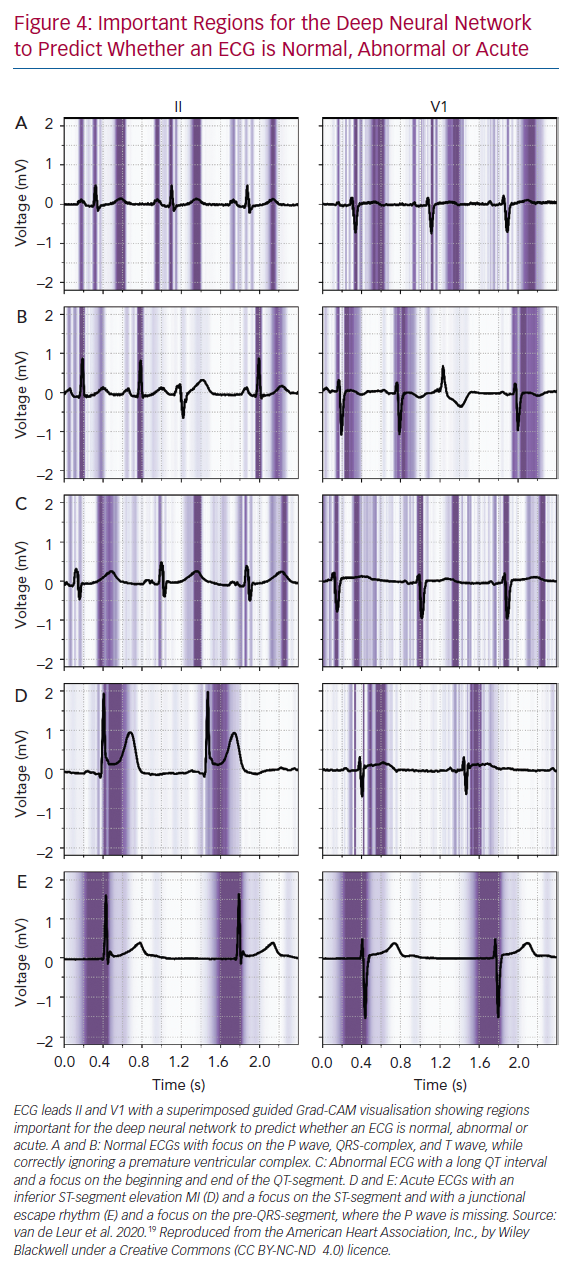
Many sophisticated ML methods are considered black boxes as they have many model parameters and abstractions. This is in contrast with the more conventional statistical methods used in medical research, such as logistic regression and decision trees, where the influence of a predictor on the outcome is clear. The trade of complexity of models and interpretability for improved accuracy is important to acknowledge; with increased complexity of the network, interpretation becomes more complicated. But interpretability remains important to investigate false positives and negatives, to detect biased or overfitted models, to improve trust in new models or to use the algorithms as a feature detector.95 Within electrophysiology, few studies have investigated how the AI algorithms came to a certain result. For DNNs, three recent studies visualised individual examples using Guided Grad-CAM, a technique to show what the networks focus on. They showed that the DNN used the same segment of the ECG that a physician would use (Figure 4).19,27,96–98
Visualisation techniques may provide the ECG locations which the algorithms find important, but do not identify the specific feature. Therefore, the opportunity to identify additional ECG features remains dependent on expert opinion and analysis of the data by a clinician is still required. Visualisation techniques and their results are promising and help to increase trust in DNNs for ECG analysis, but additional work is needed to further improve the interpretability of AI algorithms in clinical practice.99,100
Uncertainty Estimation
In contrast to physicians or conventional statistical methods, DNNs struggle to inform their users when they do not know and to give uncertainty measures about their predictions. Current models always output a diagnosis or prediction, even if they have not seen the input before. In a real-world setting, clinicians acknowledge uncertainty and consult colleagues or literature but a DNN always makes a prediction. Therefore, methods that incorporate uncertainty are essential before implementation of such algorithms is possible.101
Ideally, the algorithm provides results only when it reaches a high threshold of certainty, while the uncertain cases will still be reviewed by a clinician.101 For DNNs, several new techniques are available to obtain uncertainty measures, such as Bayesian deep learning, Monte Carlo dropout and ensemble learning, but these have never been applied in electrophysiological research.102 They have been applied to detect diabetic retinopathy in fundus images using DNNs, where one study showed that overall accuracy could be improved when uncertain cases were referred to a physician.103 Another study suggested that uncertainty measures were able to detect when a different type of scanner was used that the algorithm had not seen before.35 Combining uncertainty with active or online learning allows the network to learn from previously uncertain cases, which are now reviewed by an expert.104
Ethical Aspects
Several other ethical and legal challenges within the field of AI in healthcare are yet to be identified, such as patient privacy, poor quality algorithms, algorithm transparency and liability concerns. Data are subjected to privacy protections, confidentiality and data ownership, therefore requiring specific individual consent for use and reuse of data. However, by increasing the size of the data set, anonymisation techniques used nowadays might be inadequate and eventually result in the identification of patients.105,106 As large data sets are required for DNNs, collaboration between institutions becomes inevitable. To facilitate data exchange, platforms have been established to allow for safe and consistent data-sharing between institutions.107 However, these databases may still contain sensitive personal data.54,108 Therefore, federated learning architectures are proposed that provide data-sharing while simultaneously obviating the need to share sensitive personal data. An example of this is the anDREea Consortium (andrea-consortium.org).
Another concerning privacy aspect is the continuous data acquisition through smartphone-based applications. In these commercial applications, data ownership and security are vulnerable. Security between smartphones and applications is heterogeneous and data may be stored on commercial and poorly secured servers. Clear regulations and policies should be in place before these applications can enter the clinical arena.
Data sets contain information about medical history and treatment but may also encompass demographics, religious status or socioeconomic status. Apart from medical information, sensitive personal data might be taken into account by developed algorithms, possibly resulting in discrimination in areas such as ethnicity, gender or religion.54,108–110
As described, DNNs are black boxes wherein input data is classified. An estimate of the competency of an algorithm can be made through the interpretation of DNNs and the incorporation of uncertainty measures. Traditionally, clinical practice mainly depends on the competency of a clinician. Decisions about diagnoses and treatments are based on widely accepted clinical standards and the level of competency is protected by continuous intensive medical training. In the case of adverse events, clinicians are held responsible if they deviated from standard clinical care. However, the medical liability of the DNN remains questionable. Incorrect computerised medical diagnoses or treatments result in adverse outcomes, thereby raising the question: who is accountable for a misdiagnosis based on an AI algorithm.

To guide the evaluation of ML algorithms, in particular DNNs, and accompanying literature in electrophysiology, a systematic overview of all relevant threats discussed in this review is presented in Table 1.
Conclusion
Many exciting opportunities arise when AI is applied to medical data, especially in cardiology and electrophysiology. New ECG features, accurate automatic ECG diagnostics and new clinical insights can be rapidly obtained using AI technology. In the near future, AI is likely to become one of the most valuable assets in clinical practice. However, as with every technique, AI has its limitations. To ensure the correct use of AI in a clinical setting, every clinician working with AI should be able to recognise the threats, limitations and challenges of the technique. Furthermore, clinicians and data scientists should closely collaborate to ensure the creation of clinically applicable and useful AI algorithms.
Clinical Perspective
- Artificial intelligence (AI) may support diagnostics and prognostics in electrophysiology by automating common clinical tasks or aiding complex tasks through the identification of subtle or new ECG features.
- Within electrophysiology, automated ECG diagnostics using deep neural networks is superior to currently implemented computerised algorithms.
- Before the implementation of AI algorithms in clinical practice, trust in the algorithms must be established. This trust can be achieved through improved interpretability, measurement of uncertainty and by performing external validation and feasibility studies to determine added value beyond current clinical care.
- Combining data obtained from several diagnostic modalities using AI might elucidate pathophysiological mechanisms of new, rare or idiopathic cardiac diseases, aid the early detection or targeted treatment of cardiovascular diseases or allow for screening of disorders currently not associated with the ECG.